
Добрый вечер друзья. Сижу я такой, читаю, и вдруг, в скайпе сообщение:
[21:48:00] : Првиет)
[21:48:03] : расскажу вам как кетлетистам)
[21:48:08] : мб и знаете в курсе как увеличиьт скорость чтения из таблицы оракловойв кетле?
Ну мы конечно не в курсе. Так как база стоит на сервере в непонятном месте и основным ограничением является канал. Однако если вы хотя бы в локальной сети с базой, это будет полезно знать.
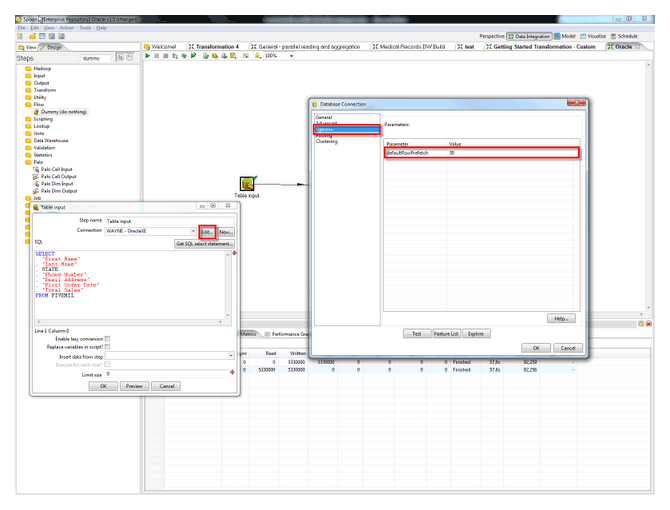
Когда вы используете шаг «Table input», вы можете резко увеличить производительность данного шага, немного подкрутив настройки JDBC драйвера. Для этого необходимо изменить свойство «defaultRowprefetch» к примеру на 20-ть. По умолчанию там установлено 10-ть. Дословно название этого поля можно перевести как «строки по умолчанию упреждающей выборки». Суть заключается в том что фактически значением данного свойства вы устанавливаете количество строк отдаваемых сервером за 1-о обращение через драйвер. Так как количество вы это увеличили, следовательно количество обращений уменьшится и увеличится скорость.
Попробуйте сами протестировать, но помните, что чем дальше б\д, тем бесполезнее данный способ.
Для визуального понимания:
Всего вам доброго.
Спасибо, что написали эту статью
Со вставкой не сталкивались на MS SQL insert / update, очень медленно вставляет ?
Сталкивался, работает хорошо. В одной из моих систем на базе mssql достаточно стабильно и хорошо работает. Пример: «каждый месяц грузится порядка 1.5 млн записей после закрытия месяца.» Даже реализовал для этой системы веб интерфейс, что бы пользователи могли запускать обмен на портале самостоятельно. Конечно шаг insert / update работает не очень хорошо если таблица очень большая, нет индексов или сложный ключ обновления.
я из oracle переношу данные в mssql через трансформацию table input -> table output порядка 18тыс. строк , но приходится делать trucate table и заливать данные, что не есть хорошо. insert / update вставляет эти данные около 10-15 минут, очень долго. А обновлять необходимо часто. Индексов нет.
В таблице в которую вставляется 50тыс. записей. Вообщем нужна репликация данных из oracla в mssql. не подскажете куда копать ?
не видя задачи сложно сказать
Но на вскидку:
1) Попробуйте реализовать через Call db procedure. Это будет работать быстрее чем insert / update и даёт больше гибкости с точки зрения оптимизации загрузки. К примеру можно в orace создать колонку с хеш суммой данных строки. Далее в процедуре, смотрите хеш если нашли, запись отбрасывается если не нашли то insert обычный или update в зависимости от условий. Скорость работы зависит от того как быстро отработает процедура на одной записи т.е. это опять нужно экспериментировать с индексами или с поиском дубликатов.
2) Грузить во временную таблицу как вы делаете «table input -> table output with trucate» , а потом refresh через процедуру, которую вам нужно будет самому написать. Плохо работает когда записей >5 млн. но это уже зависит от железа конечно в большей мер где база данных стоит.
3) «table output + error handler» — вешаем уникальный ключ на таблицу. Все записи которые выходят из шага table output по ошибкам отправляем в хранимую процедуру для обновления. Этот способ хорош когда уникальный ключ есть и количество обновляемых записей по крайней мере не превышает 50% от общего объёма.
Мне сложно сказать, какой из вариантов будет для вас самым оптимальным, так как я не вижу самих данных. Но всеми этими способами я пользовался из-за того что insert / update слишком медленный. Попробуйте сделать по способу 2-а, он просто более универсальный и явно даст подсказку о производительности самой базы данных. Т.е. если ваша процедура refresh всё равно будет работать медленно в самой базе данных, то думаю ускорить загрузку средствами kettle не получится.
в очередной раз спасибо.