
И вот очередная ночь и скрипт почти готов. Ты пытаешься прогнать его на всём объёме данных, и вдруг на твоих глазах наворачиваются слёзы, грудь сковывает отчаянье и боль за потраченное время не даёт давить по клавишам и двигать мышь. Ты увидел красными буквами надпись в логе обработке «out of memory» у шага для чтения xml файла. Ну ни чего, ты собираешься с мыслями и копаешься в документациях, примерах и прочем, что выдаст тебе «старший брат». Ну что же, я постараюсь избавить тебя от лишних телодвижений и показать путь покороче.
Разбор большого XML файла мы рассмотрим на самой большой таблице «Федеральной информационной адресной системы»
Качаем базу ФИАС и распаковываем её.

Рис.1 — Страница загрузки базы ФИАС
Создаём трансформацию.
Она будет иметь вот такой вот вид:
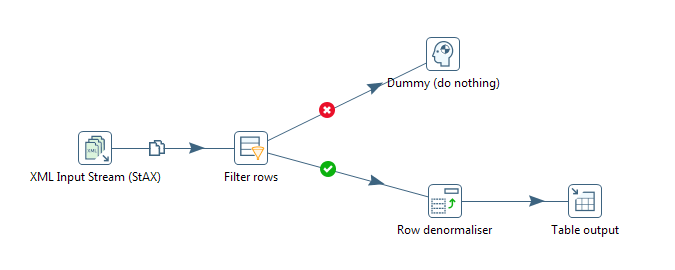
Рис.2 — Скрипт загрузки xml файла базы ФИАС
Ключевой шаг, который позволит нам зачитывать XML это «XML Input Stream (StAX)».
Исчерпывающую информацию по стандарту StAX вы можете найти самостоятельно, рекомендую прочитать статью для общего развития. Настройки данного шага у меня выглядят вот так:

Рис.3 — Настройка шага «XML Input Stream (StAX)»
Давайте посмотрим на строки которые мы получаем на выходе из шага «XML Input Stream (StAX)»
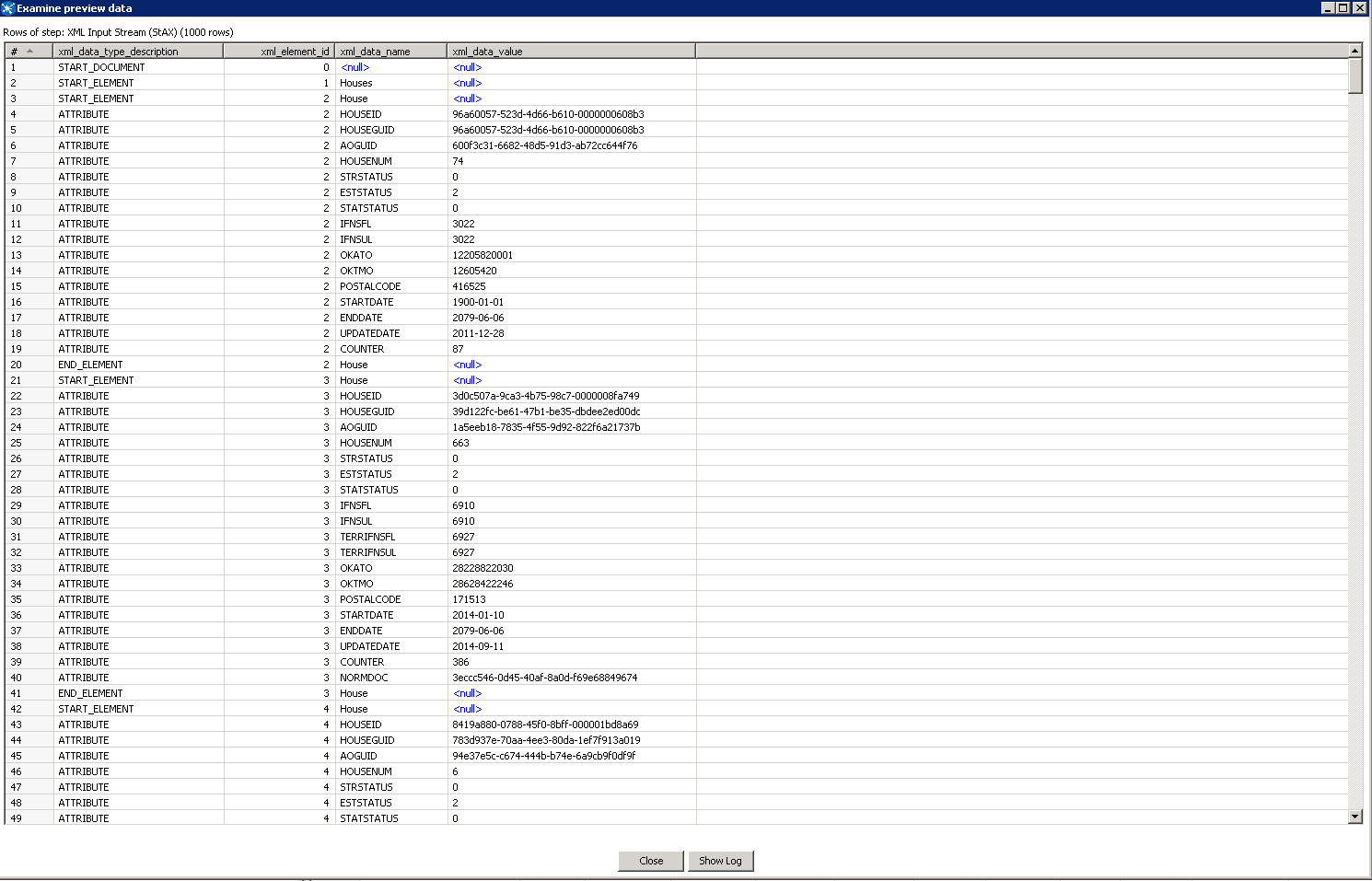
Рис.4 — Строки на выходе «XML Input Stream (StAX)»
Исходя из структуры XML файла базы ФИАС мы видим, что нам нужны только атрибуты всех XML элементов «House».

Рис. 5 — Структура файла HOUSE базы ФИАС.
Это означает что нам достаточно будет извлекать только атрибуты XML элементов. Все остальные извлечённые строки нам не нужны и мы их отрезаем при помощи фильтра.

Рис. 6 — Настройки шага «Filter rows»
Теперь у вас есть два варианта:
- Загрузить данные в БД и там уже преобразовать в нужную форму.
- Сразу провести преобразование и загрузить в базу данные в более удобоваримом виде. Я рекомендую именно это вариант. Связано это с тем, что даже наш боевой Oracle с трудом переваривал преобразование такого большого объема данных и приходилось обрабатывать их кусками. Даже написание оптимизированной процедуры для этого будет менее эффективным, чем провести преобразование на уровне kettle data-integration. Я думаю вы уже сами догадались почему. Если всё же нужно пояснить, пишите в комментариях
Собственно я реализовал преобразование при помощи шага «Row denormaliser». Более подробно мы рассматривали его в статье «Data Integration — Kettle | Шаги «Row normaliser» и «Row denormaliser». ( UNPIVOT / PIVOT )» Сейчас я приведу только текущие настройки для файла с домами базы ФИАС. Настоятельно советаю определять типы на этапе преобразования. Делать так как показано в данном шаге является плохим тоном, обязательно определите типы для для каждого поля.

Рис. 7 — Настройка шага «Row denormalise»
Ну и последним нашим шагом, отправляем всё это в базу данных.

Рис. 8 — Шаг вывода результатов
Пример как обычно по ссылке:lageXML
Доброго времени суток.
Подскажите как можно изменить значение node в xml файле.
Цель в джобике поменять путь к файлу транстформации.
Если открыть джоб это node:
//job/entries/entry/filename там прописывается полный путь к трансформации вот этот путь необходимо поменять.
Огромное спасибо. Вы сэкономили мне день и познакомили с очень полезным инструментом. В оракл домики влились за 20 минут.