
Я вам советую не сильно радоваться в надежде на халявный универсальный способ разбора HTML страниц. Это задача всегда решается под конкретный сайт с использованием разнообразных инструментов. Но да, наша трансформация для разбора HTML страницы действительно будет состоять не больше чем из 4-х шагов.
В данном посте мы рассмотрим два важных вопроса, которые, поверьте мне, очень будут вас выручать.
- Использование сторонних библиотек Java в kettle data-integration
- Управление потоком данных при помощи кода.
Честно говоря, если бы это было недоступно, то я сомневаюсь, что стал бы вообще использовать kettle data-integration в повседневной жизни.
Приступимс:
Для разбора HTML страницы мы будем использовать стороннюю Java библиотеку Jsoup. Её необходимо скачать и разместить jar файл в директории \\data-integration\lib . Всё, мы добавили библиотеку и теперь можем её использовать на полную катушку. Да, это так просто и это радует. Только не забудьте перезапустить графическую среду разработки kettle data-intagretion, иначе работать новая библиотека не будет.
Теперь давайте набросаем шаги для нашей трансформации. Она будет выглядеть примерно так:
- Получить url страницы (Тут я использовал шаг Generate rows)
- Получение html файла (Шаг HTTP client)
- Разбор html (Шаг Modified Java Script Value)
- Запись данных в файл. (Microsoft Excel Output)
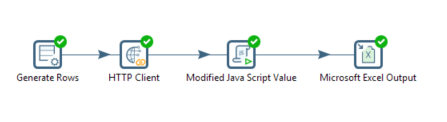
Рис.1- Шаги трансформации.
1. Получить url страницы.
Передавать url для разбора вы можете совершенно любым доступным методом. Нам для демонстрации подойдёт шаг Generate rows. Его настройка проста и понятна.

Рис.2 — Настройки шага Generate Rows.
2. Получение html файла.
И опять всё достаточно просто.
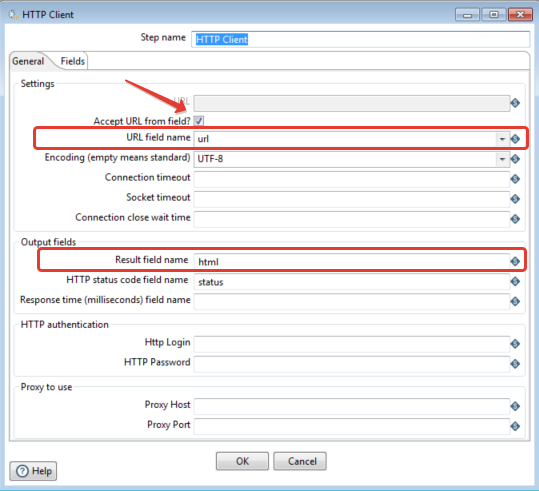
Рис.3 — Настройки шага HTTP client.
3. Разбор html.
И вот кульминационный и самый сложный момент нашей трансформации.
//Script here
jsp=org.jsoup.Jsoup;
doc=jsp.parse(html);
// Jsoup позволяет использовать html селекторы. В данном примере в элементе div с классом news-wrapper_ получаем все элементы h3 с классом b-item__title внутри которого находится ссылка(тег «а») с непустым атрибутом «href»
els=doc.select('div.news-wrapper_ h3.b-item__title a[href]');
// Размер полученного массива со ссылками
var l=els.size();
for (var i=0;i<l;i++) {
//Cоздать новый объект строки.
var row = createRowCopy(getOutputRowMeta().size());
//Найти индекс первого поля прилагаемой этим шагом
var idx = getInputRowMeta().size();
// Заполнить каждое поле (обратите внимание, как индекс увеличивается)
row[idx++]=els.get(i).attr("href"); // Это поле выходящее поле link так как оно первое
row[idx++]=els.get(i).text(); // Это выходящее поле name так как оно второе
putRow(row);
}
//Устанавливаем статус у входящей строки,для пропуска,что бы не отправлялась на выход данного шага.
trans_Status = SKIP_TRANSFORMATION;
Возможно вам поможет небольшое графическое описание.
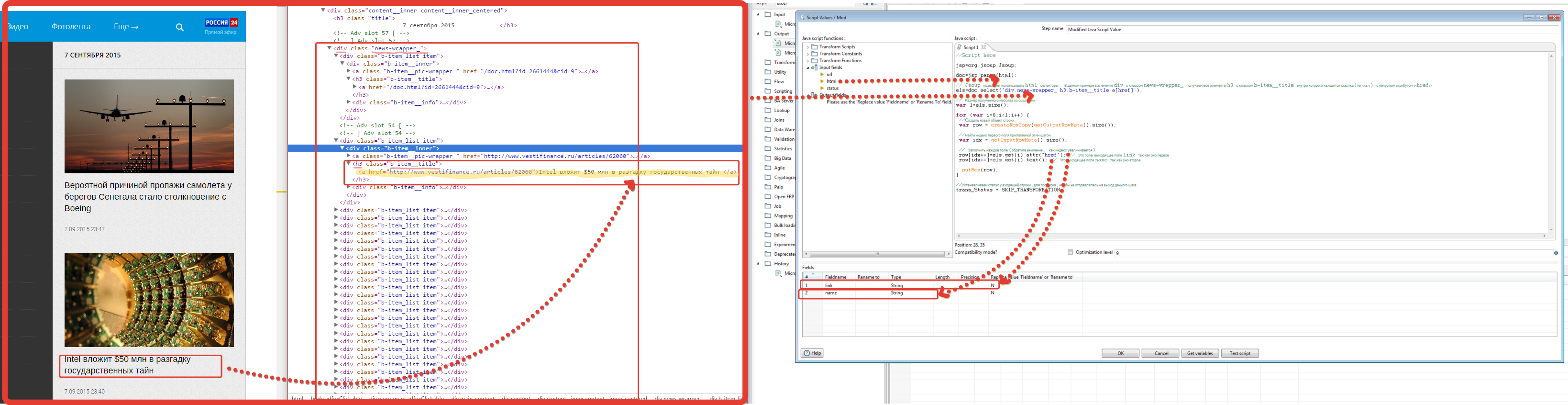
Рис.4 — Пояснение некоторых моментов
4. Запись данных в файл.
Как вы будете сохранять результаты, решать вам. Я использую шаг «Microsoft Excel Output» Даже писать про него ни чего не буду т.к. это элементарно.
Пример как обычно по ссылке: htmlParser
Пожалуйста, прежде чем задавать вопросы, посмотрите документацию и примеры хотя бы у используемой нами библиотеки: документация, примеры.